第1段階:学習
STEP1
教師用検体の
パルスを切り出し
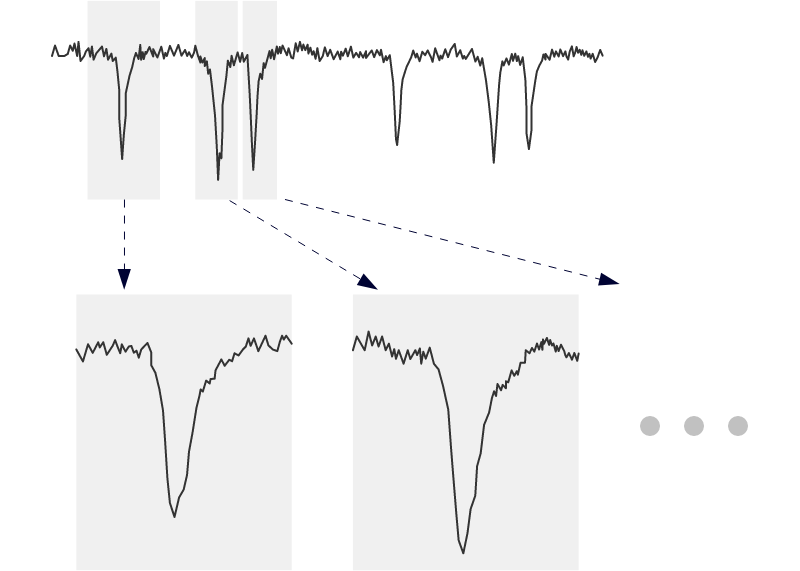
ポアセンサモジュールおよび微粒子計測装置から取得したデータは、粒子通過パルスの部分のみを切り出します。ノイズを含む大量のデータから、いかに高い精度でパルスを切り出すか。これがAI識別の精度を決める最重要技術の一つです。
アイポアは、独自のパルス切り出しアルゴリズムで、AI学習および識別に最適なベースライン推定とパルス切り出しを実現。高精度のAI識別を実現します。
STEP2
教師にするパルスの
特徴量を抽出
切り出したパルス1つが、1個の粒子通過の情報を含んだ波形となります。ここからAI学習や識別に使われる特徴量を抽出します。特徴量とは、波形を特徴付ける物理量です。たとえば、持続時間(tw)、パルス高(Ip)、非対称性(At)などが一般的な説明では使われますが、アイポアAI識別ではこれらよりはるかに多くの独自特徴量でAI解析を行います。
どのような特徴量を解析対象にするかは、まさにノウハウのかたまり。AI粒子識別を最高の精度で実現するために最適の特徴量を抽出しています。
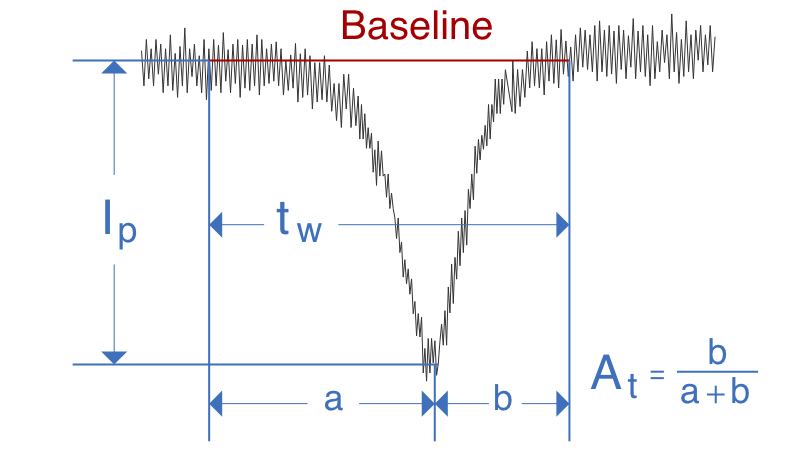
※Ip、tw、Atは一般的な特徴量の例です。アイポアAI識別で使われているものとは異なります。
※大腸菌を3μmポアセンサで計測した波形
STEP3
学習
(識別境界最適化)
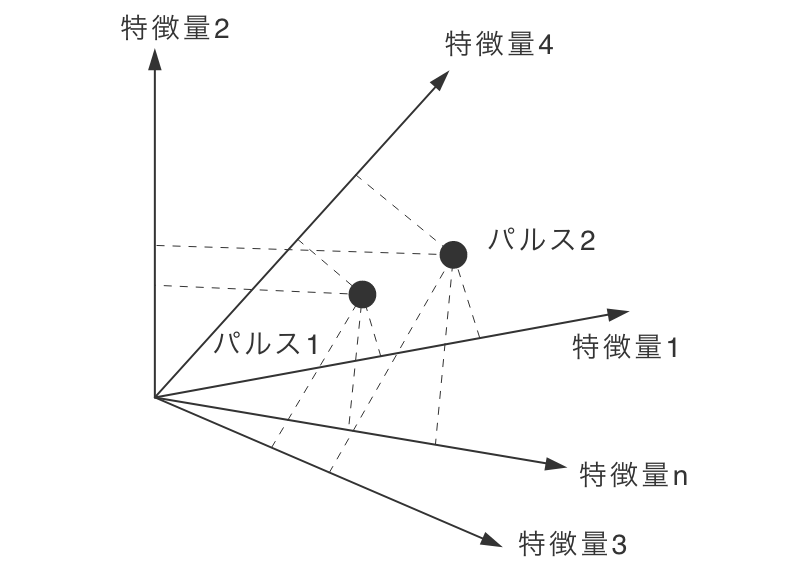
Step2で、パルス1つあたりn個の特徴量を抽出したとします。各パルスはn次元空間内の1点(特徴量ベクトルといいます)で表されます。
教師データ/ラベルとしてM個のパルスが計測できたとすると、n次元の特徴量空間に分布したM個の点のプロットとして表現されます。AI学習とは、このような特徴量ベクトルのプロットにおける、最適な識別境界を算出することです。
細菌3種の実測パルス特徴量を使った識別境界導出の例
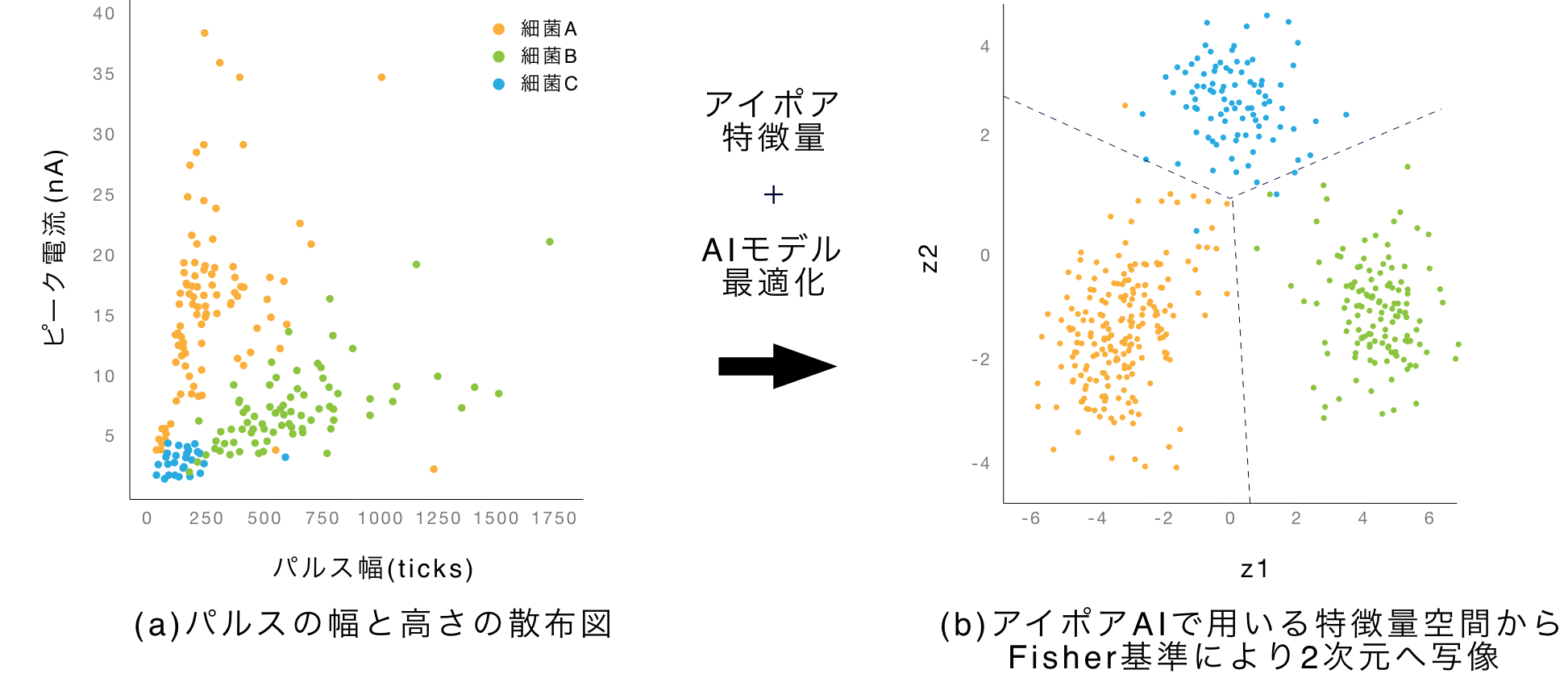
細菌3種の実測パルスから抽出した特徴量の2次元プロット。
(a)は、パルス幅および高さの分布。特徴量を例示したのみで、アイポアAI識別でこの特徴量空間を利用して識別しているとは限らない。
(b)は、アイポアAI識別で利用している特徴量分布を、Fisher基準の最適化で2次元に線形写像したもの。点線は直感的な説明のためにフリーハンドで識別境界を記入したもので、LDAによる境界でもアイポアAIが算出した境界でもない。
(a)は、細菌3種の実測パルスの、パルス幅とピーク電流(高さ)の分布です。同じ粒子であっても、パルス形状は様々であり、細菌ごとに特徴量が大きくオーバーラップしていて、このままでは識別は困難なことがわかります。 (b)は、(a)と同じパルスデータからアイポアAI識別で使う多数の特徴量を抽出して、多次元空間でのプロット(特徴量ベクトル群)を作った後、LDA(Linear Discrimination Analysis)という手法で2次元に写像したものです。同じパルスデータからとった特徴量でも、分離できていることがわかります。
AIモデル最適化によって、目視では区別がつかない波形データであっても、このような統計的で正しく識別できるような写像を探す。これがAIモデル最適化の一例です。
STEP4
最適化したAIモデルの性能評価
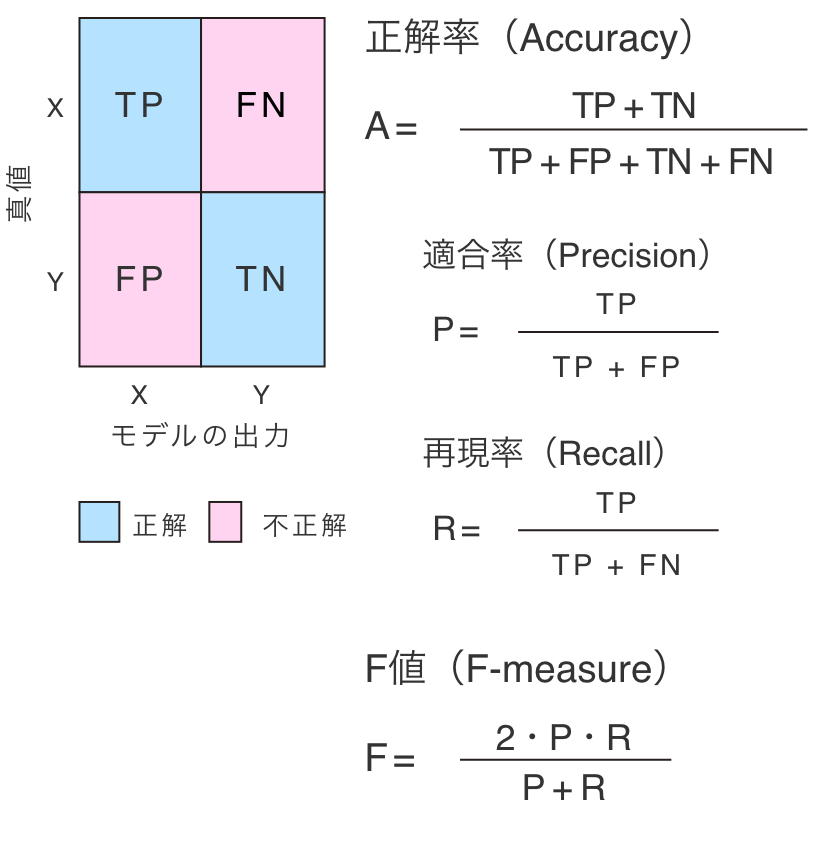
AIモデルの最適化が終わると、アイポアAIシステムは、学習に利用した教師データ/ラベルを用いて、AIモデルの性能評価を自動で行います。アイポアAIシステムが提示する代表的な性能評価指標が、交差検定により行う、混同行列と、正解率およびF値です。
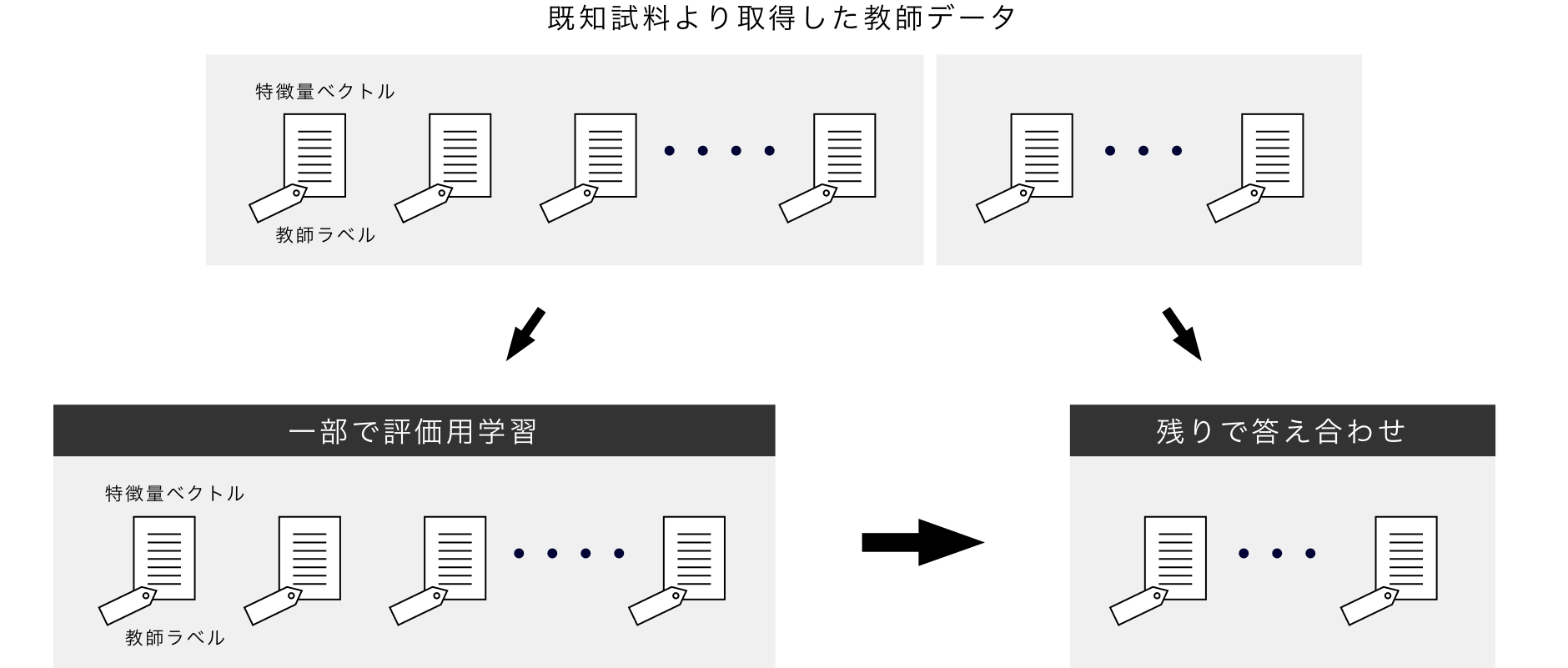
交差検定 ー 学習済AIモデルの性能評価
既知試料の計測で得られた教師データは、パルスごとの特徴量と教師ラベルの組です。その組の一部を評価用学習に、残りの組を答え合わせ(検定)に用います。
限られた教師データを有効に使い、正確な評価を行うため、評価用学習に使う組と、検定に使う組を入れ替えながら複数回検定を行い、この平均で学習済AIモデルの性能を評価する方法を、交差検定という手法です。
答え合わせの結果、パルス1つごとに、学習させたAIモデルが識別した結果が正しいか否かがわかります。
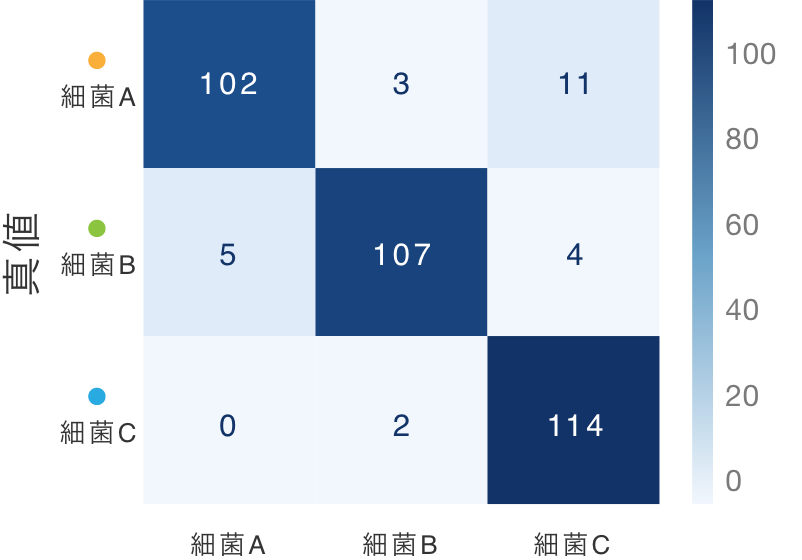
混同行列 ー 学習済AIモデルの正誤表
学習済AIモデルは、パルス1つごと(ポア通過粒子1個ごとに)それが何であるかを識別します。この識別がどの程度正しかったのかを、視覚的に表現するのが、混同行列です。混同行列の対角線が正解、それ以外が不正解です。
図は、Step03で示した細菌3種の教師データ116パルスを、交差検定により識別させた混同行列です。たとえば、本当(真値)は細菌Aだったパルス116発のうち、この学習済AIモデルは102発を正解しました。一方、このモデルは細菌Aのうち3発を誤ってBに、11発をCと識別しました。
Step3の細菌3種識別の混合行列
学習させたAIモデルによる識別結果
正解率とF値 ー 性能を1つの数値で表現
混同行列は、学習済AIモデルの正確性をよく表します。しかし多くの場合、モデルの性能を数値で表す指標が有用です。アイポアAI識別システムでは、正解率、F値の指標を用います。
正解率は全パルス数に占める正解(XをXと、YをYと識別したもの)の割合です。文字通り、モデルがどの程度言い当てたかの指標です。問題は、XとYのパルス数が大きく偏っているような場合の性能表示には適さない点です。
F値は適合率と再現率の調和平均です。適合率は、真値がXであった粒子の中でモデルの出力がXであったものの割合、再現率は、モデルの出力がXであったものの中で真値がXであったものの割合です。これの調和平均をとることで、正解率の問題を回避します。
第2段階:識別
AI学習が終わり、学習済AIモデルを作ったら、未知検体の識別が可能になります。未知検体の計測(Step05)、パルス切り出し(Step06)の処理は学習時と同じです。あとは、アイポアAIシステムに未知検体として登録(Step07)するだけで、未知検体の種類を推定します。
STEP7
未知検体の
種類を識別
Step04で作成した学習済AIモデルは、識別境界によって区切られる識別領域を持っています。ここに、Step06で抽出した未知検体パルスの特徴量ベクトルは、いずれかの識別領域に属します。
たとえば図でパルス1は細菌Cの領域に属するので、細菌Cであると判断されます。
ただし、1つの未知検体から取ったパルスも教師データと同様に分布を持ちます。このため一般には、未知検体パルスは、図のように複数の領域にまたがります。
アイポアAI識別では、このような場合の識別判断にMSPRT(注)(Multi class Sequential Probability Rate Testing)という手法を用いて未知検体の種類を識別します。
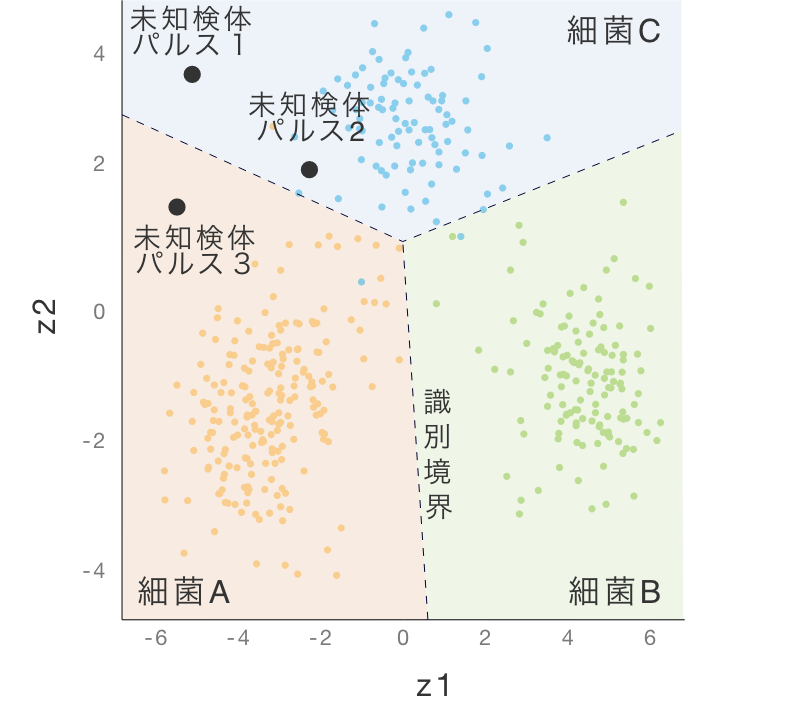
未知検体パルスの特徴量ベクトルが、
学習済AIモデルのどこにあるかで識別
(注)C. W. Baum et. al., IEEE Tran. Info. Theory, Vol.40, No.6 (1994)
A. Bronstein, Report of Computer Science Department, Technion – Israel Institute of Technology (2009)